Saturday
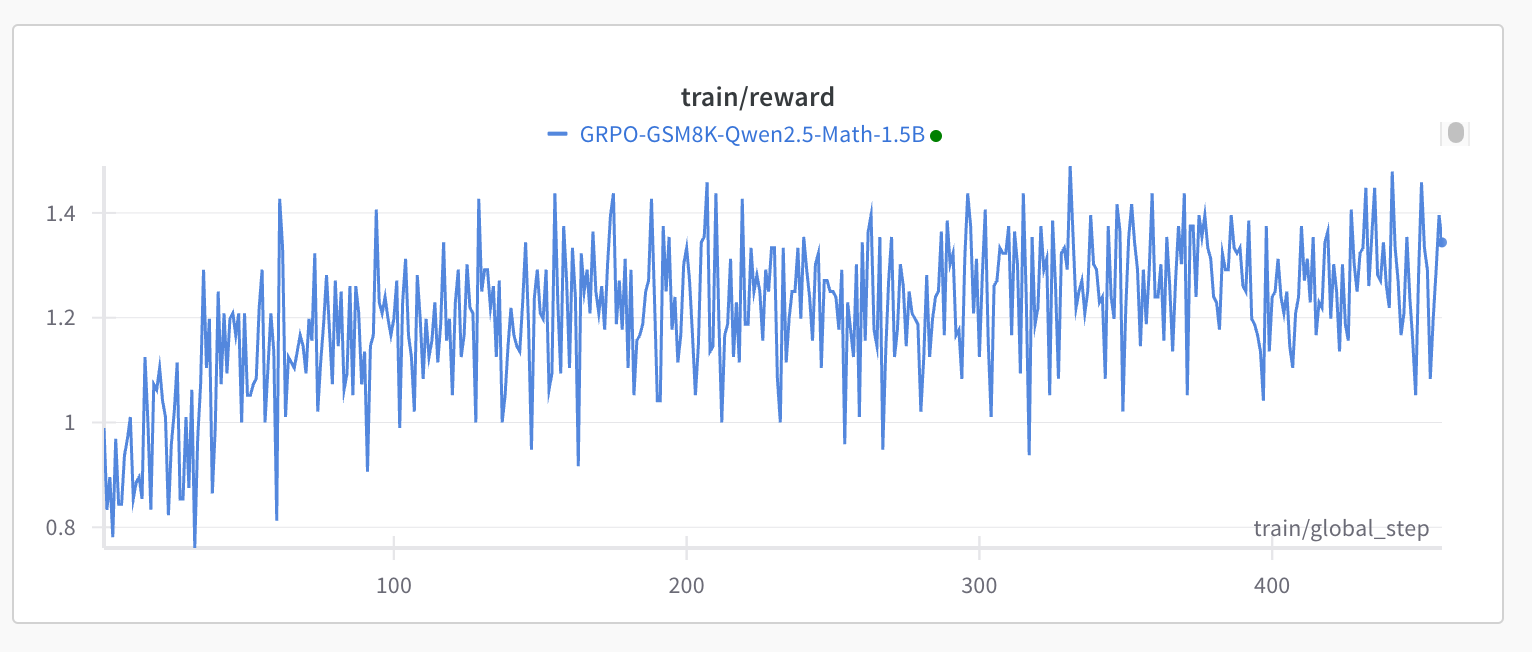
Fourth attempt on reproducing DeepSeek R1’s GRPO on small models — The third fourth time is the charm. I can successfully run this repo, without activating vLLM (keep vllm=true uncommented in the source code), on a single NVIDIA RTX 4090 with 24 GB CUDA memory, training the Qwen2.5-Math-1.5B model with the gsm8k dataset.
I used the following pyproject.toml:
[project]
name = "grpo"
version = "0.1.0"
description = "DeepSeek R1 reproduction using small models"
readme = "README.md"
requires-python = ">=3.11, <=3.12"
dependencies = [
"torch",
"transformers",
"datasets",
"peft",
"wandb",
"vllm",
"trl",
"flash-attn",
]
[tool.uv]
no-build-isolation-package = ["flash-attn"]
[tool.uv.sources]
torch = [
{ index = "pytorch-cu121", marker = "sys_platform == 'linux' or sys_platform == 'win32'" },
]
torchvision = [
{ index = "pytorch-cu121", marker = "sys_platform == 'linux' or sys_platform == 'win32'" },
]
[[tool.uv.index]]
name = "pytorch-cu121"
url = "https://download.pytorch.org/whl/cu121"
explicit = trueAnd the following command to run the repo:
uv run train.pyI obtained the following result after around 6 hours and over 450 steps:
Third attempt on reproducing DeepSeek R1’s GRPO on small models — Will Brown’s GRPO reproduction uses the openai/gsm8k dataset with 7470 samples, rather than the Countdown Game dataset in the two previous attempts — TinyZero and Mini-R1 — which is much more meaningful. It has been shown by others that even the small Qwen2.5-0.5B model can be trained from 41.6% to 51% on the gsm8k test set. I will try to reproduce this result some time, but for now it ran out of CUDA memory for a single NVIDIA RTX A4500 with 20 GB of CUDA memory, even for training the Qwen2.5-0.5B model.
Home server at $2000 for DeepSeek R1 at 4-bit quantization — $2000 home server, running the DeepSeek R1 671b model at 4-bit quantization and 3.5-4 tokens per second.
NVIDIA hosts DeepSeek R1 — much slower than Lambda Labs.
OpenAI o3-mini — On ChatGPT Plus, the rate limits are 150 messages per day for o3-mini-medium, and 50 messages per week for o3-mini-high. The latter is designed to be the strongest model on coding.